Learning to Ignore
April 2018
Introduction
One of the main use cases of unsupervised learning is to learn a representation of data which we hope will be useful on downstream tasks. For instance, in model-based reinforcement learning (MBRL), we learn a model of the environment and then use the model to help achieve the RL task. This is a type of semi-supervised problem, since modeling the environment is mostly unsupervised and maximizing the reward of the RL task is supervised. The unsupervised learning task has more learning signal since it often models all the information present in the data, in comparison to the supervised task. This increase in learning signal can be beneficial on small problems where most of the information present in the data is related to the downstream supervised tasks. However, as we try to scale to more complex datasets, there is much more information in the dataset that is irrelevant to downstream tasks.
For instance, consider the increase in information in the following image datasets: MNIST -> SVHN -> CIFAR and beyond. If we care about classification, then as the complexity increases, modeling the data in an unsupervised fashion becomes less effective since there is more information not relevant to classification. Another example to consider is an agent interacting in the real world. Lets say the agent is walking down the street, it could model something important like the movement of the people walking by or it could model something less important such as the movement of the leaves on the trees. The agent could easily spend all of its finite compute modeling the infinite information in the world. So the point is, as we scale unsupervised learning to more complex problems, we need to ignore information.
Side note: I use the concept of ignoring interchangeably with attention, since with a fixed budget of attention, to ignore means we are putting more attention on some other aspects of the data.
Learning to Ignore Given a Trained Network
The scenario I'm going to consider is one where we previously had access to some supervised learning signal (labeled data/ RL reward) which lead to a trained network for that task and now we need to use that network to ignore the information that is irrelevant to the network. This isn't unsupervised because the network is providing supervision, and it isn't a typical supervised setting since we no longer have access to the supervised signal, just the trained network. The assumption is that the information relevant for the first task will be the same for the downstream tasks. This is a strong assumption, but it's a start.
In the context of MBRL, the idea is to:
- Train a network to accomplish some task
- Model only the parts of the environment that are relevant to the trained network
- Use the environment model to learn new tasks
How can we model only the parts of the environment that are relevant to the trained network? The approach I've taken is to remove information from the frames by blurring pixels while keeping the output of the network unchanged. More specifically, I'm modifying the frames by taking a mixture of the real frame with a blurred frame:
where is the real unmodified frame, is a blurred version of the frame, is the mixing coefficient (also referred to as a mask), and is the resulting frame mixture. The mixing coefficient for each pixel is learned by minimizing the following objective:
where is the output of the network given and D is some measure of divergence (I used squared error). So the objective tries to minimize the divergence between the output from the real frame and the mixed frame as well as maximize the amount of blur in the mixed frame. Rather than learn the mask for each pixel of each frame, we learn a network which outputs the mask given a frame.
Experiments
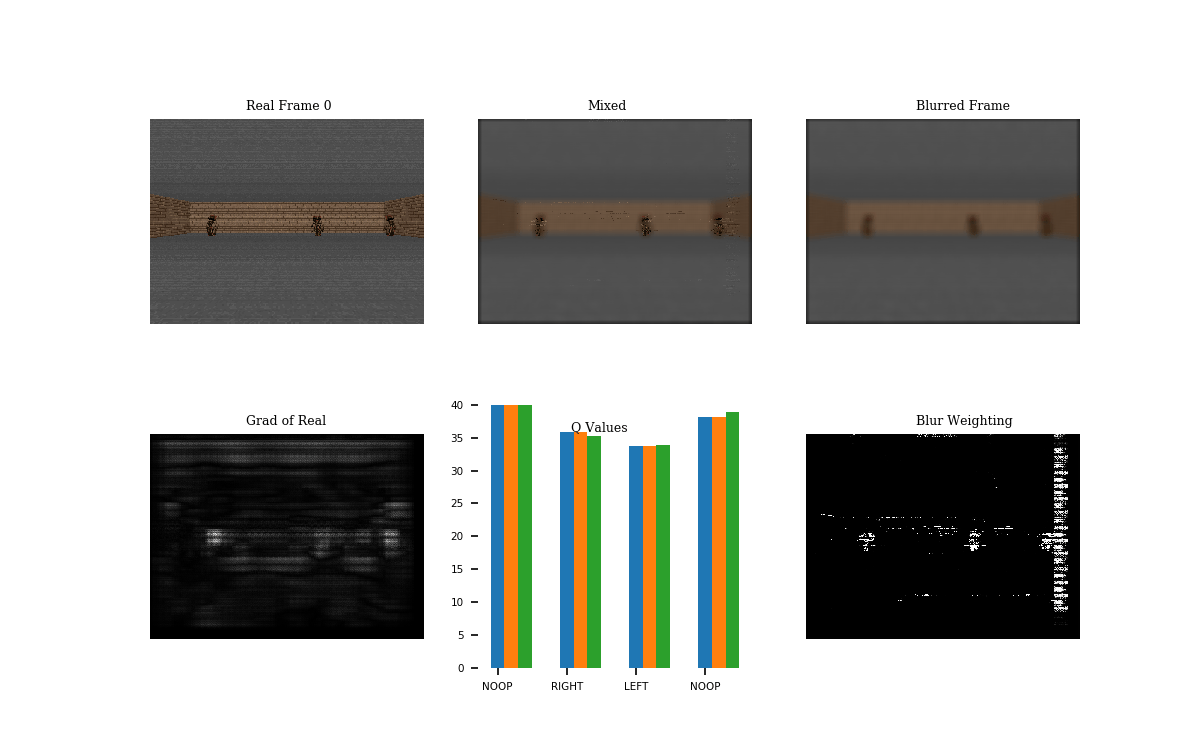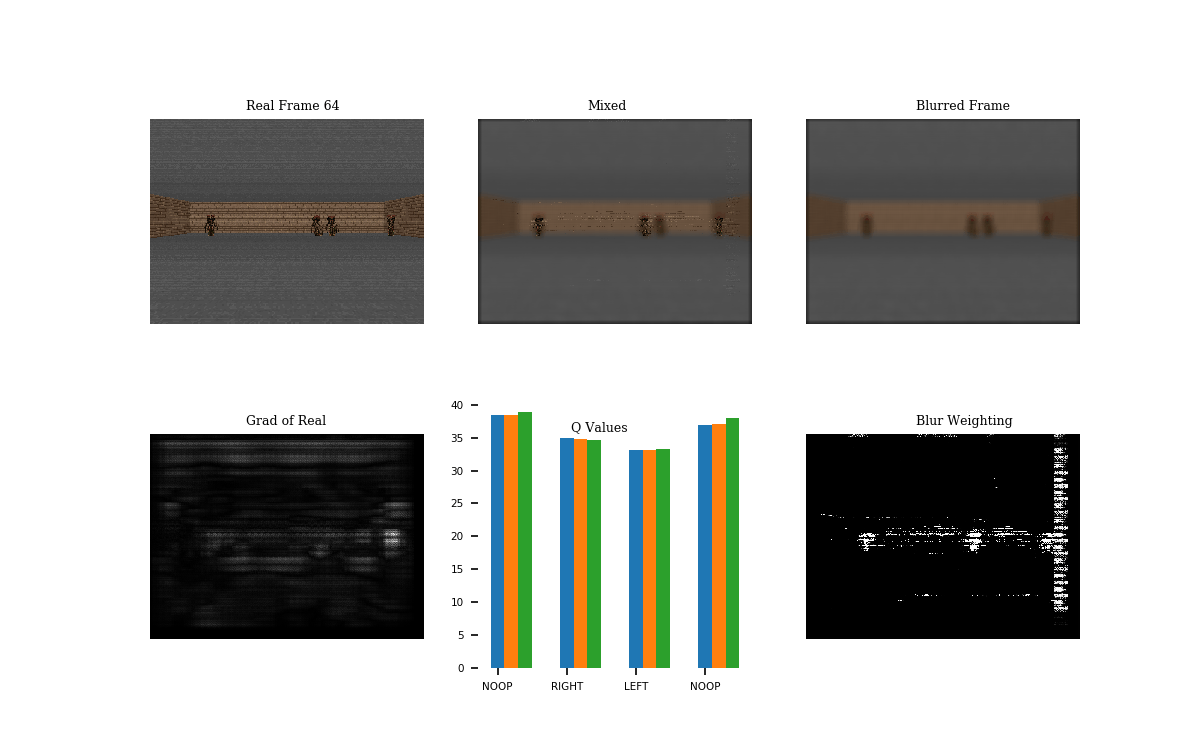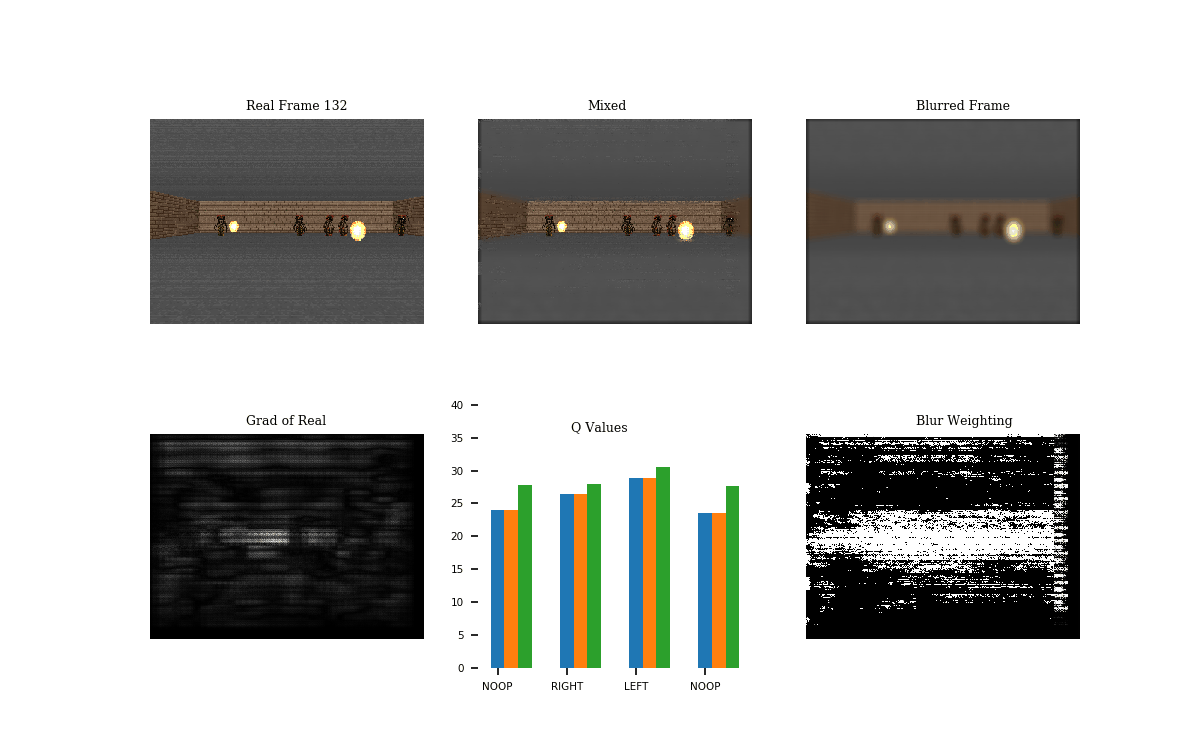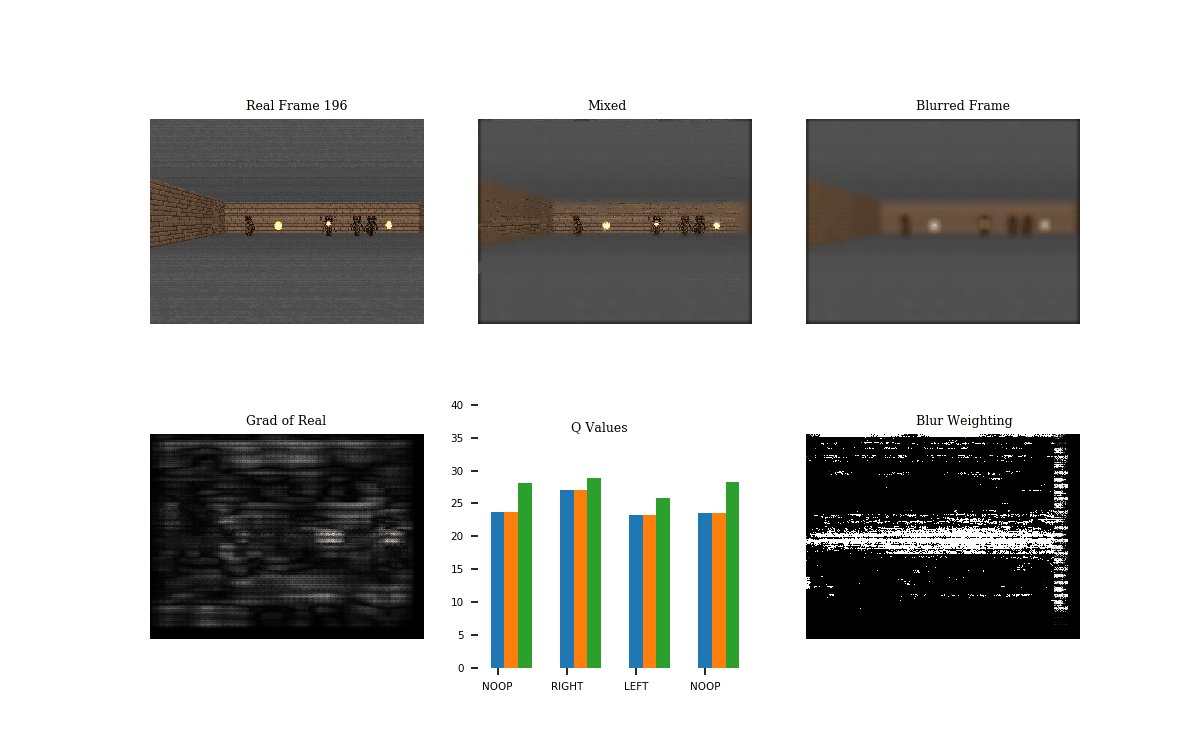
Following the World Models paper, I tried this procedure on Doom. This game scenario involves dodging the balls of fire. I trained a network to play the game using DQN. See GIF 1 below for the result.
The Q-values show the output of the Q-network given the real (blue), mixed (orange), and the blurred (green) frames. Notice that the Q values of the real and mixed are nearly the same, unlike the Q-values of the blurred frame. The blur mask (blur weighting, ) does blur the majority of the top and bottom parts of the frame, but it could likely be improved.
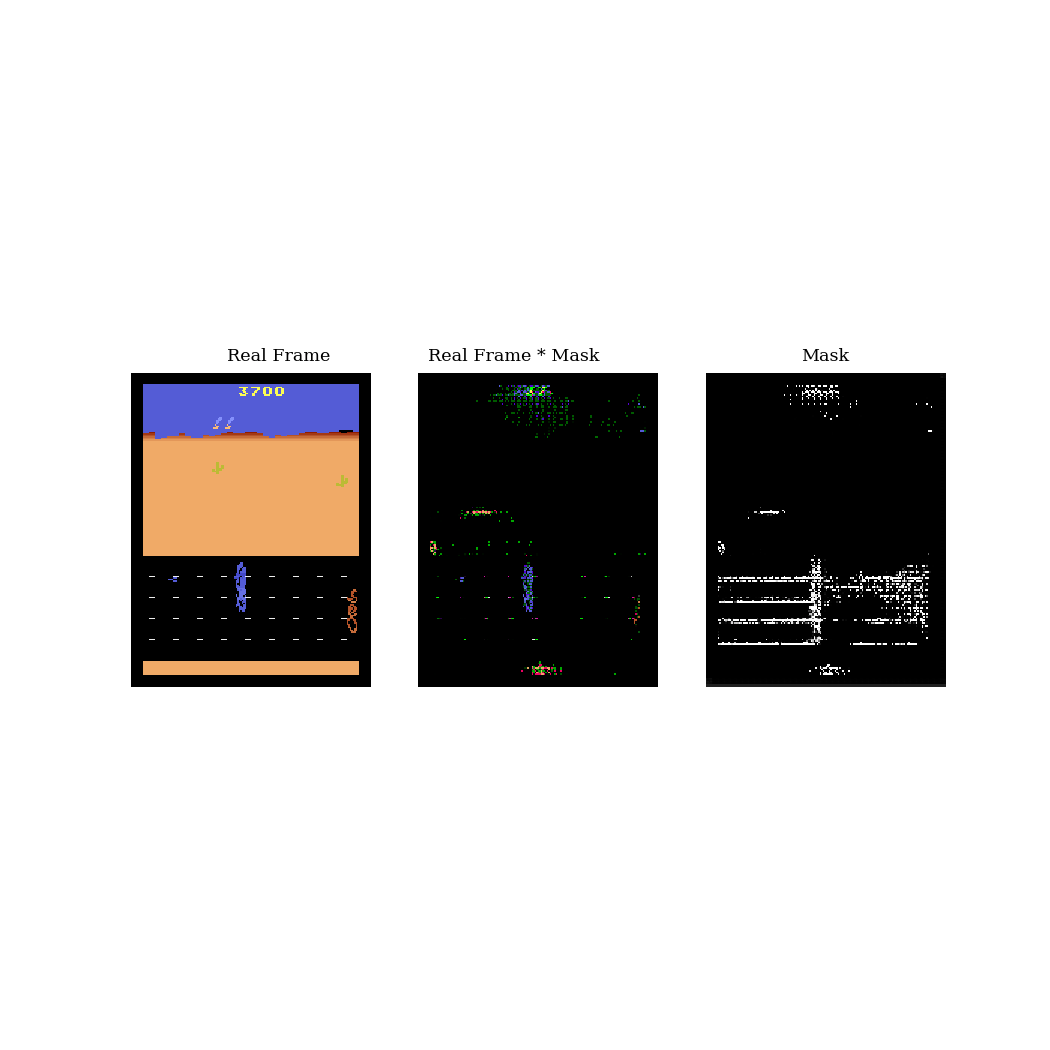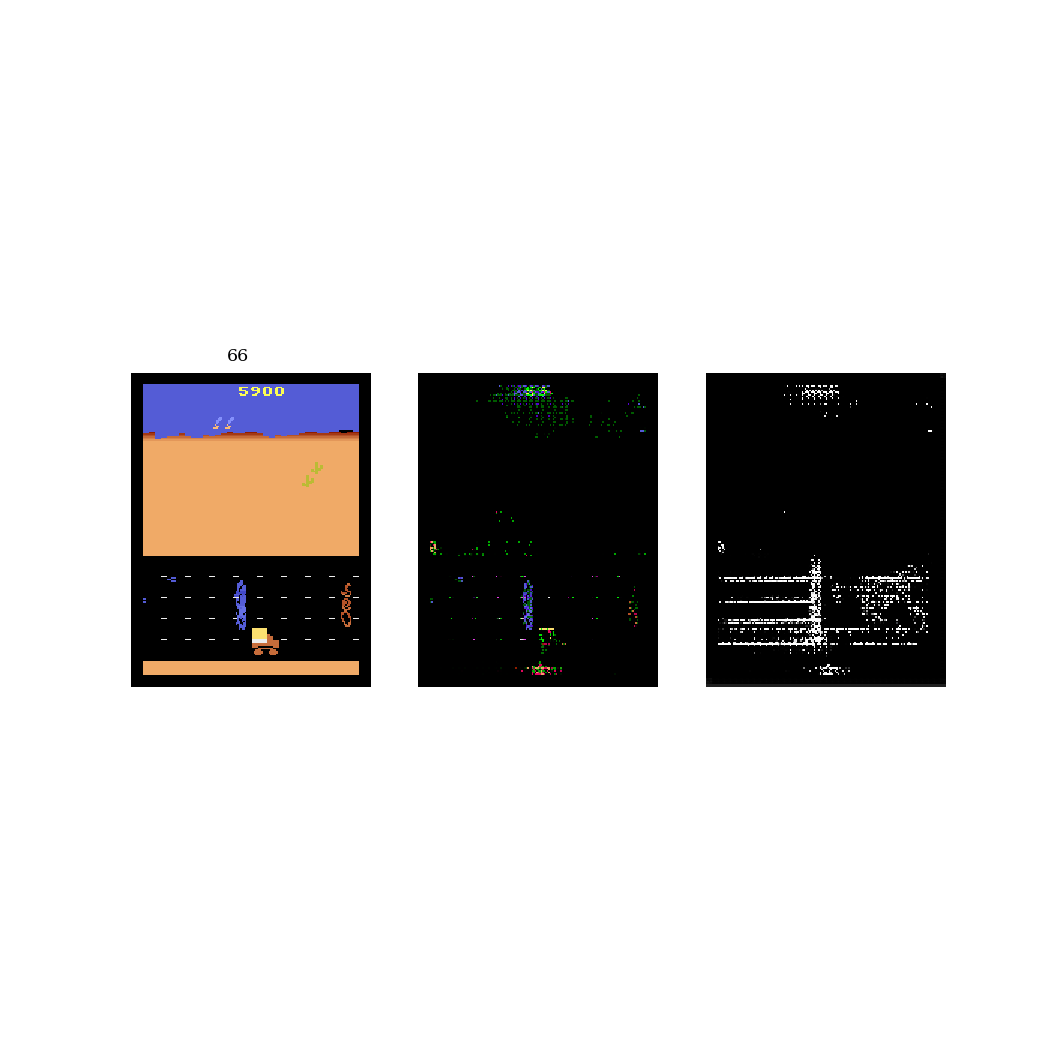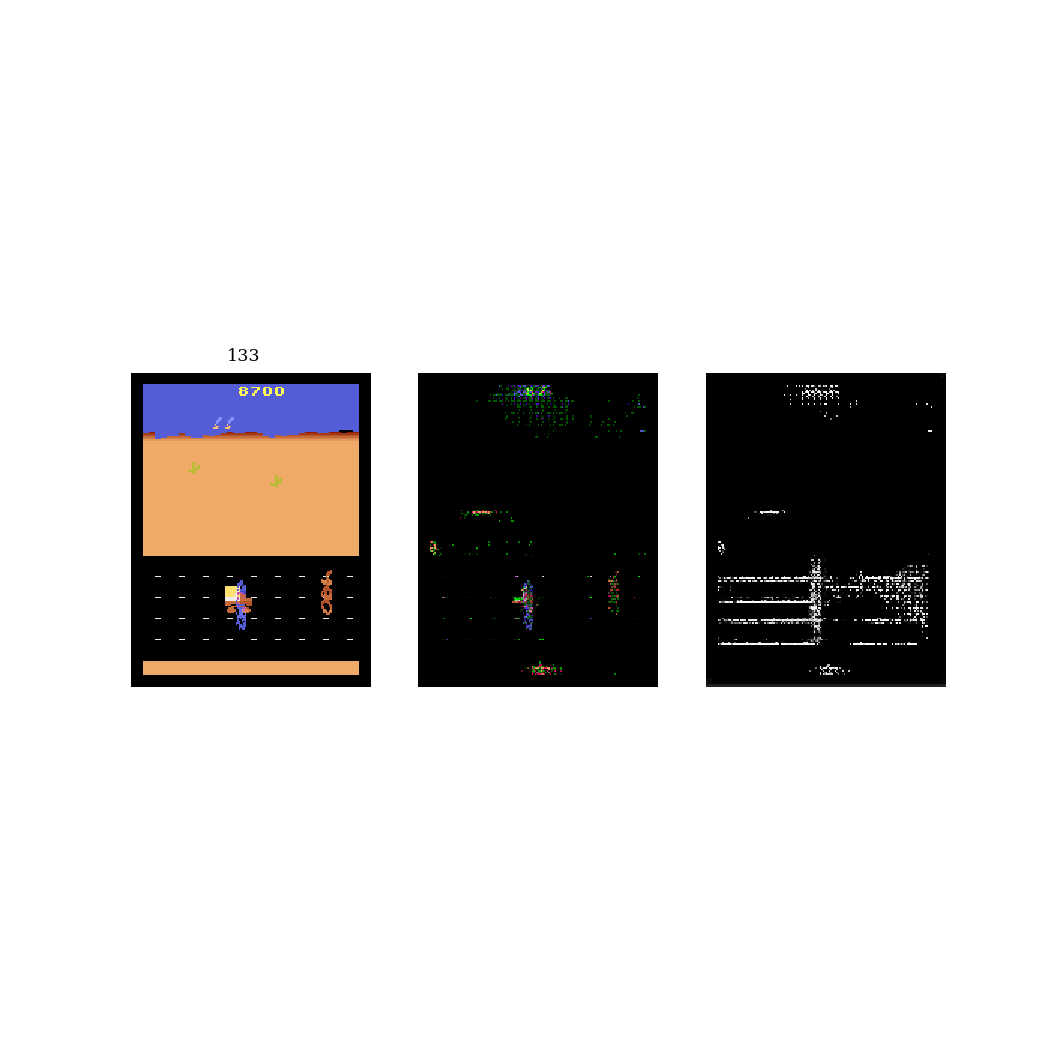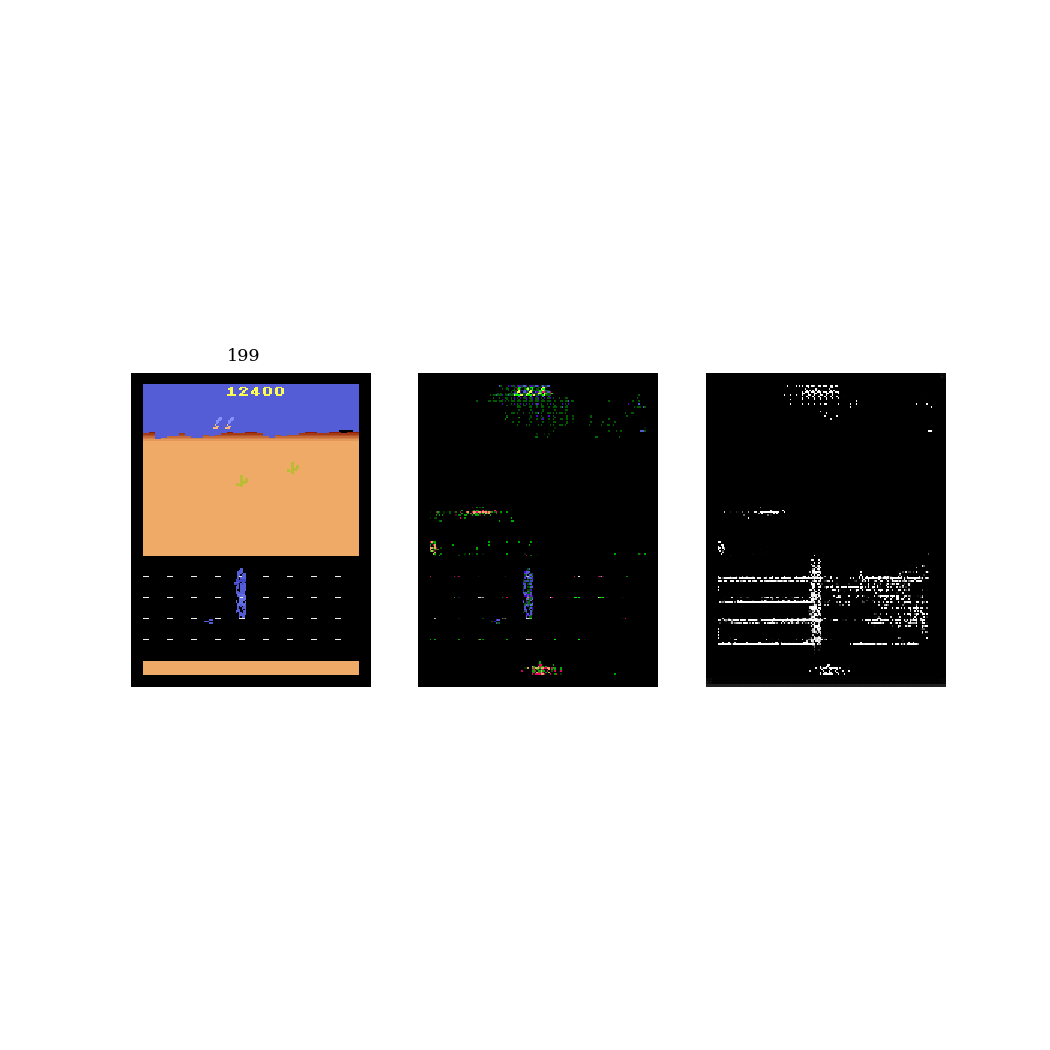
I also tried this procedure on the Atari game Road Runner. The main difference here is that the mixed frame is a mixture between the real frame and a black frame, instead of a blurred frame. See GIF 2 below. In this game, the blue road runner needs to run away from the orange coyote. As a result, the model can ignore the majority of the pixels and just focus on a small portion of the road.
Discussion
What I've shown above is just the beginning. I still need to model the modified frames, then show that it works for downstream tasks (ie. transfer learning). Also, there are two main assumptions that I need to demonstrate: 1) that on more complex environments, performing unsupervised learning will fail due to the amount of irrelevant information, and 2) that the modified frame from this procedure has less information and is therefore easier to model. The simple environments I used above are poor demonstrations of these assumptions, thus I'll need to move to more complex environments.
Besides MBRL, another use for this type of procedure is interpretability of the decision making of the RL agent. See this paper for a demonstration of this procedure for interpretability. My work above can be thought of as seeing the environment through the eyes of the agent.
There are many further questions to address regarding this work:
- How contrived is this scenario? Will it be useful for the agents of the future?
- Why even train the model on the modified frames? How about modeling a hidden layer of the Q-network?
- What about other data modalities besides images, what's the best way to remove information from other modalities?
- How to incorporate prior biases into unsupervised models so that they ignore information that is often irrelevant (ex: leaves on a tree)?
- How strong are the assumptions I've made above?
All in all, the feasibility of unsupervised learning scaled to more complex problems is questionable and this work looks to address this.